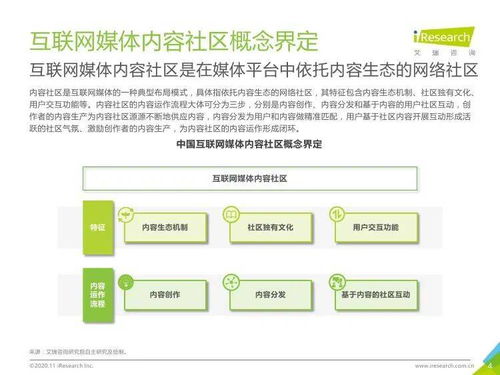
在數字化浪潮中,內容服務商管理系統正面臨著日益復雜的挑戰:用戶需求瞬息萬變、內容海量增長、個性化服務要求越來越高。中能魔力作為行業領先的內容服務商,其管理系統的核心——推薦系統——正迎來一場由大語言模型(Large Language Models, LLMs)驅動的深刻變革。這場變革不僅提升了推薦的精準度與用戶體驗,更在系統效率、內容理解與商業價值上實現了全面飛躍。
1. 深度理解:從標簽匹配到語義洞察
傳統推薦系統多依賴于用戶行為數據(點擊、瀏覽、購買)和內容標簽(類別、關鍵詞)進行協同過濾或內容匹配。這種方式在結構化數據豐富時表現良好,但面對非結構化內容(如長文本、視頻描述、用戶評論)時往往力不從心。大語言模型憑借其強大的自然語言理解能力,能夠深入解析內容的語義、情感、風格乃至隱含意圖。
中能魔力的應用實踐:系統接入LLM后,能夠自動解析新聞文章、視頻腳本、電子書摘要等非結構化內容,生成富含語義的向量表示。例如,一篇關于“新能源政策”的文章,傳統系統可能僅匹配“能源”、“政策”等標簽;而LLM能理解其討論的是“儲能技術補貼”、“碳排放交易”等具體維度,從而與用戶更深層次的興趣(如“家庭光伏投資”、“電動汽車政策”)進行精準對接。
2. 動態個性化:生成式推薦與實時交互
傳統的“千人千面”推薦多基于歷史行為,屬于“被動響應”模式。大語言模型帶來了“生成式推薦”的可能性。系統不僅能匹配現有內容,還能根據用戶當前上下文(如搜索詞、會話記錄、實時場景)動態生成推薦理由、內容摘要,甚至創造個性化的內容組合。
中能魔力的應用實踐:在用戶瀏覽“周末旅游攻略”時,系統利用LLM實時分析用戶過往的偏好(喜歡“文化古跡”還是“自然風光”)、預算水平、出行人數,并結合實時天氣、交通信息,生成一份獨一無二的“個性化周末出行方案”,而不僅僅是推薦幾個已有的旅游文章或產品。這大大提升了推薦的實用性與用戶粘性。
3. 冷啟動破局:理解新用戶與新內容
“冷啟動”問題一直是推薦系統的難題。對于新注冊用戶或新上架內容,缺乏歷史數據導致推薦質量低下。大語言模型通過分析用戶注冊信息、初始行為(如首次搜索、填寫的興趣問卷)的文本,以及新內容的完整描述,能夠快速建立高質量的用戶畫像和內容畫像,顯著縮短冷啟動周期。
中能魔力的應用實踐:新用戶首次進入平臺,在簡單選擇幾個興趣標簽后,系統利用LLM分析這些標簽的語義關聯,并參考同類用戶的群體畫像,立即提供一批高度相關的、多樣化的內容推薦,讓用戶“第一眼”就感受到系統的智能,極大改善初始體驗。
4. 可解釋性與信任構建:從“黑箱”到“透明服務”
“為什么推薦這個給我?”——大語言模型能夠生成自然語言的理由,讓推薦決策過程變得透明。這不僅能增加用戶信任,還能幫助內容服務商和平臺運營者理解推薦邏輯,進行人工校準與優化。
中能魔力的應用實踐:在每項推薦旁,系統會提供一句由LLM生成的簡明解釋,如“為您推薦此報告,是因為您近期關注了A公司的財報,且該報告深度分析了其所在的半導體產業鏈風險。”這使得推薦不再是冰冷的算法輸出,而是一種可溝通的服務。
5. 系統效能提升:自動化內容管理與運營
對于中能魔力這樣的內容服務商管理系統,LLM的價值不止于前端推薦。在后臺,LLM可以自動化完成大量運營工作:
- 內容標簽與分類:自動為海量內容生成更豐富、更準確的元數據。
- 內容摘要與提煉:快速生成文章摘要、視頻看點,用于推薦卡片展示。
- 質量審核與去重:理解內容語義,輔助識別低質、違規或高度重復的內容。
- 用戶反饋分析:自動聚類和分析用戶評論、投訴,提煉出對內容策略和推薦算法的改進建議。
挑戰與中能魔力的應對策略
融合大語言模型也非一蹴而就,中能魔力在升級過程中重點關注并解決了以下挑戰:
- 計算成本與延遲:采用混合架構,對實時性要求高的推薦路徑使用輕量化模型或Embedding緩存,對深度分析任務使用異步調用。
- 幻覺與準確性:建立嚴格的事實核查與過濾機制,將LLM的輸出與傳統推薦模型的結果進行交叉驗證,關鍵領域(如金融、醫療內容)以傳統模型為主,LLM為輔。
- 數據隱私與安全:所有用戶數據處理均在合規框架內進行,采用聯邦學習、差分隱私等技術,或使用經嚴格微調的領域私有模型,確保數據不外泄。
###
大語言模型為推薦系統,特別是中能魔力這類內容服務商管理系統,注入了前所未有的“理解力”與“創造力”。它正在將推薦從一種基于統計的匹配技術,升級為一種基于深度理解的智能內容服務。這場變革的核心在于,系統不再僅僅是“猜測”用戶可能喜歡什么,而是開始真正“理解”用戶的需求和內容的靈魂,從而為用戶創造更富價值、更貼心、更可信的個性化內容體驗,最終推動整個內容生態的繁榮與高效運轉。中能魔力的實踐表明,擁抱LLM,是內容服務商在智能化時代構建核心競爭力的關鍵一步。